TensorFlow Playgroundの仕組み
TensorFlow Playgroundの本家サイトはこちら。
本家のTensorFlow Playgroundの日本語訳を作成しましたので、本サイトと合わせてご覧ください。
TensorFlow Playgroundとは何かを言葉で説明するより一度自分の目で直接見るほうが早いので、 上記のリンクをクリックしてTensorFlow Playgroundを開き、思いつくままいろいろ自分で試してみてください。 ディープラーニングの仕組みが直感的になんとなく分かると思います。
今回、直感的になんとなく分かる、で満足できなくなった人のためにこのサイトを作成しました。
実際にTensorFlow Playgroundは何をしているのか、数ある設定項目はどんな意味を持つのか。
本ページではTensorFlow Playgroundの裏側を詳細に解説します。
私自身は機械学習の研究者でもなく、関連した仕事をしているわけでもありません(そういった仕事に興味はありますが)。 ですのでところどころ誤りや間違いが見つかると思います。 もし誤りを見つけられましたら私のツイッター までご連絡ください。
参考文献
はじめにこのサイトを作るにあたって参考にした資料を載せておきます。 ここで解説する内容は大なり小なりこれらのサイトの解説を自分の言葉でまとめ直したようなものです。 私の拙い文章が分かりにくいと感じたらこれらの参考文献を直接読んでいただいてかまいません。
- Neural Network TensorFlow入門講座
- TensorFlow Playgroundでわかるニューラルネットワーク
- Neural Network and Deep Learning
- Deep Learning An MIT Press book
先頭の丸山氏による「Neural Network TensorFlow入門講座」は初学者でも非常に理解しやすい内容になっています。 パワーポイントでニューラルネットワークの基礎について非常にわかりやすくまとまっていますので一度目を通してみることをおすすめします。
上から2番目のGoogleの佐藤氏による「TensorFlow Playgroundでわかるニューラルネットワーク」と本サイトはTensorFlow Playgroundを 題材としている点でコンセプトは似ていますが、こちらのサイトはニューラルネットワーク本論よりかはPlayground上の用語や仕組みの解説に 重きをおいています。
3番目の「Neural Network and Deep Learning」はMichael Nielsen氏による英文のドキュメントです。私のWebサイトで使う数式は こちらのサイトの説明をかなり参考にしています。文章自体もユーモアがふんだんに取り入れられた、技術解説サイトとは思えない素晴らしいWebサイトです。
4番目の「Deep Learning」は非常に詳細にDeep Learningについて解説しています。文量が非常に多く私もまだ全て読み終えていませんが、 内容を全て理解できればディープラーニングの基礎が身についていると言っても過言ではないと思います。無料で読めるHTML版の他に、米国amazonでは 印刷された本が販売されています。2017/2/7現在amazonのAI分野でベストセラーとなっていました。
このサイトの言い回しや例えは上記の参考文献の影響を多大に受けています。似たような言い回しがいくつか見つかると思いますがご容赦ください。
Playgroundの仕組み概要
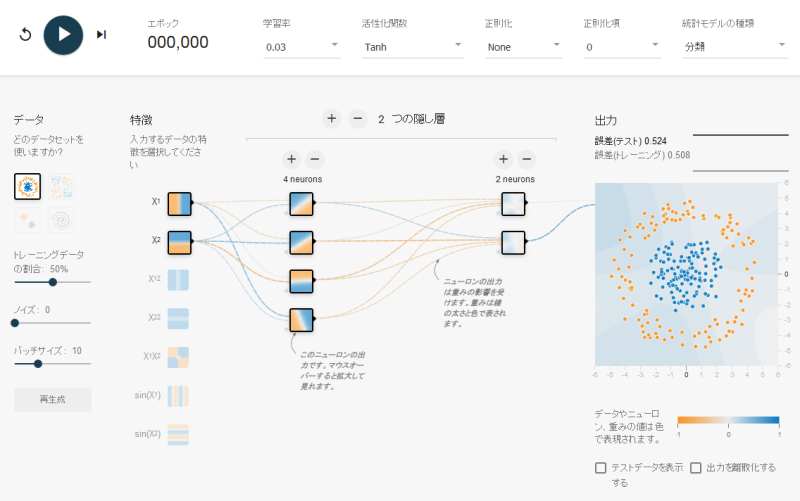
上の図はTensorFlow Playgroundのスクリーンショットです。上部に学習率や活性化関数などの全体的な設定が、左側には学習させるデータの設定が、 真ん中に四角いボックスで表されたニューロン、およびニューロンで構成されたニューラルネットワークが、そして右側にニューラルネットワークの最終的な出力結果 が表示されています。これらの詳細は後ほど解説します。
左上にある再生(▶)ボタンを押すと機械学習が始まります。右側の出力結果の平面上に点在した赤と青の点々に沿うようにヒートマップの色が変化していく様子が見れるはずです。 そして点々の色とヒートマップの色の分布が互いに近づいてくるに従って誤差の数値が小さくなる様子も確認できるはずです。
TensorFlow Playgroundのニューラルネットワークは、事前にプロットされた赤と青の点々の分布を学習し、これらの点がどのような規則に従って分布しているのかを 推測しようとします。
ダーツを例に別の角度から説明します。
壁に正方形の板と取り付けてダーツを投げ、当たった場所によって得点が変わるゲームがあるとします。
また、どこに当たれば何点というのは事前に分かっておらず、投げたダーツは必ず板のどこかにあたるものとします。
さらに得点は-1点から+1点の間の値をとるものとします。
TensorFlow Playgroundでは「どこにダーツを投げれば何点入るか」を、いくつかダーツを投げてみて推測します。
ダーツを投げて+1点であればその点を青で塗り、-1点であれば赤で塗ります。
当然板のすべてのありとあらゆる場所に隙間なくダーツを投げてデータを取れば推測する必要もなく確実な結果が分かりますが、
現実的に無限回ダーツを投げて全ての座標についてデータを取るのは不可能です。
いくつかの学習用データサンプルを元にダーツの得点分布を機械学習で推定してしまうのがTensorFlow Playgroundです。
言い換えると板上の各座標 $x,y$ についてダーツの得点分布 $f(x,y)$ を機械学習によって推定します。
もっとも、データの標本を元に真の分布を推測する手法自体は統計学で扱うポピュラーな手法でありTensorFlow Playground独自の話ではありません。
TensorFlow Playgroundでは、統計分析の手法としてフィードフォワード型ニューラルネットワーク(多層パーセプトロン, MLP)を使い 機械学習させることによって真の分布を推定します。
TensorFlow Playgroundは教師あり学習をモデルにしています。
これは、入力(今回は $x,y$ 座標)に対して正解の出力($f(x,y)$)が紐付いたデータサンプルがいくつか事前に用意されている機械学習モデルです。
TensorFlow Playgroundの出力の平面にプロットされた赤と青の点々が、その学習用のデータサンプルです。
これらのサンプルを使い、問題と回答のデータを学習させることでネットワークを鍛えています。
学習用サンプルを使ってある程度ネットワークが鍛えられると、$x,y$の入力から$f(x,y)$を高い精度で推定できるようになります。
このようにしてみるとまるで統計学の勉強をしているような錯覚に陥るかもしれません。機械学習といえば、例えば猫の画像を読みこませるとコンピュータが それを猫だ、と判定する画像認識や、手書き文字認識、音声認識で世間を騒がせています。 ダーツの得点分布が分かることと機械が猫を認識できるようになることとどういう関係あるのか、これが理解できるようになるためにはある程度数学的な 解説が必要になってきます。
このサイトではなるべく数式に頼らない説明を心がけていますが、一歩深く踏み込むためには必要最小限の数学が必要になることを覚悟しておいてください。
機械学習の何がセンセーショナルだったかというと、コンピュータが画像や音声などの非構造化データの高い精度での認識に成功したことです。
コンピュータはこれまで構造化データの処理に力を発揮してきましたが、非構造化データまで扱えるようになったことで多くの人を驚かせました。 非構造化データに対する構造化データとは、あるデータに対してコンピュータにこのデータはどういうデータだという情報をデータ本体とは別に持たせたデータのことです。 例えば"東京都千代田区1-1-1"という文字列を見ると、これはすぐに日本のどこかの住所だな、我々人間には分かりますが、 コンピュータは単なる文字列としか認識できません。そのためコンピュータがこれを住所と認識するためには
"東京都千代田区1-1-1" : "住所"
などのようにこの文字列は住所を表している、という情報を別途人間が付与する必要がありました。 皆様お馴染みのエクセルにしても、データを集めたシートを作る際に先頭一行にヘッダーを設ける場合が多いと思います。
例えばエクセルで下記のようなデータを作るとします。
| 郵便番号 | 電話番号 | 氏名 |
| 000-1111 | 000-0000-0000 | 鈴木太郎 |
| 111-0000 | 111-1111-1111 | 佐藤一郎 |
| 999-1234 | 03-0000-0000 | 田中三郎 |
この場合、一行目のヘッダにその列データの意味の情報が付与されています。
これが構造化データの一例です。データに対して、そのデータが何を意味するものかあらかじめ人の手によってラベルづけされています。
対する非構造化データとは、これらのヘッダがないデータと考えてください。画像、音声は非構造化データの代表例ですが、 上の表についてヘッダを取り除いた場合これも非構造化データとなります。この場合、「000-1111」は郵便番号のような感じもしますが、 コンピュータは事前にこれが郵便番号とは知らないので、上の表から郵便番号を取ってこいとコンピュータに指示をしてもコンピュータは どれが郵便番号か分かりません。
機械学習はこういった非構造化データを人力に頼らずコンピュータ自身でデータを構造化するための効率の良い仕組み、と考えるとよいでしょう。
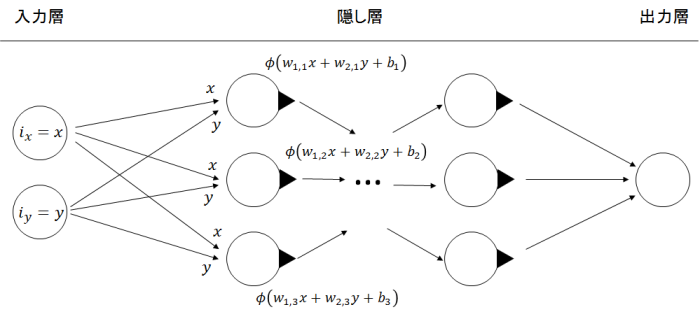
補足: ニューラルネットワークを関数としてみる
上ではダーツを例にしましたが、もう少し一般化しましょう。
ニューラルネットワークとは、入力ベクトル $$ \boldsymbol{x} = \begin{pmatrix} x_1 \\ x_2 \\ ... \\ x_n \end{pmatrix} = \{\boldsymbol{x} \mid \boldsymbol{x} \in \mathbb{R^n} \} $$ を受け取り、出力ベクトル $$ \boldsymbol{f}(\boldsymbol{x}) = \{\boldsymbol{f} \mid \boldsymbol{f} \in \mathbb{R^m} \} $$ を返す関数と見ることができます。
ダーツの例に当てはめると、 入力ベクトル: $ \boldsymbol{z} = \begin{pmatrix} x \\ y \end{pmatrix}; x,y \in \mathbb{R} $ に対して、出力ベクトル: $f(\boldsymbol{z}) = \{ f \mid f \in \{1,-1\} \}$ となります。
ダーツの例では出力は-1か+1の2通りで、1次元ベクトル=スカラー値です。
ネットにはMNISTデータベースを使って手書きの数字を機械学習でコンピュータに認識させる機械学習チュートリアルがたくさんありますが、 MNISTのケースでは入力ベクトルは手書き数字のビットマップ画像のビット列のベクトル、 出力ベクトルは入力した手書き画像の数字が$i$である確率$P_i$を$i=0からi=9まで並べた$ 確率ベクトル$(P_0,...,P_9)$になります。
ただし、確率ベクトルから最も確率の大きい1つを抜き出したものを出力ベクトルとするものもあります。
このように、現実世界の問題をうまく入力ベクトル・出力ベクトルにモデル化することができれば機械学習で驚くような結果が得られる可能性があります。
機械学習の基礎をマスターすることができれば、応用事例は自分のアイデア次第になります。 この「自分のアイデア次第」という部分が私達のように機械学習を勉強する人の大きなモチベーションなります。
機械学習では、上に書いた出力関数 $f$ の形状をサンプルデータの学習を通じて推測しようとします。
ニューラルネットワークではこの$f$の形状は主にニューロンの重み $w$ とバイアス $b$ で決まります。
それ以外に活性化関数$\phi$というフィルターの役割を持つ関数も$f$の形状に寄与します。 この辺りについては後ほど説明します。
いずれにしろ、ネットワークを関数として見るというのは非常に新鮮な感覚です。
より詳しい説明に移る前に、ニューラルネットワークの概観や画面に表示されているいくつかの設定項目について説明します。
ニューラルネットワークについて
巷には非常にわかりやすくまとまったWebサイトが溢れているため このサイトではニューラルネットワークについてゼロから解説することはしません。 ニューラルネットワークの概要を知りたい方は参考文献の欄にも記載したNeural Network TensorFlow入門講座 を一読ください。
英語が読める方はNeural Network and Deep Learning もおすすめです。
ここではTensorFlow Playgroundを理解するのに最低限必要な前提知識としての説明に留めます。
ニューラルネットワーク(多層パーセプトロン, MLP)は入力層、隠し層、出力層の3種類の層からなっています。
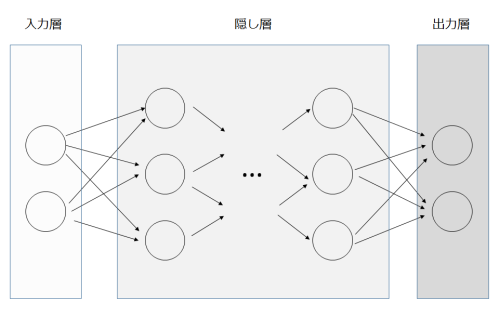
何を入力とするか、何を出力として得たいかの機械学習モデルができると、入力層と出力層については層の中のニューロンの数やベクトルの要素の意味などが定まります。
例えばダーツの例では入力ベクトルはダーツを当てるx,y座標、出力ベクトルはその座標にダーツを当てた時に得られる得点です。 MNISTの手書き数字認識の場合は入力ベクトルは手書き数字の画像のビット列、出力ベクトルは0〜9のどの文字であるかの確率です。
ですが、隠し層については機械学習モデルが定まったあともすぐには決められません。モデルにより隠し層の層の数はいくつか最適なのか、それぞれの層の中の ニューロンの数はどのくらいが良いのかは経験や試行錯誤の上決まっているようです。
隠し層の数やニューロンの数を増やせば、ネットワークのパラメータが増えるためネットワークが柔軟になりますが、 同時にパラメータの計算コストが上がるため、単純に数を増やせばよいわけではありません。
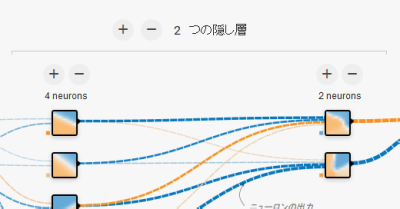
TensorFlow Playgroundでは上図中のプラス(+)ボタンとマイナス(-)ボタンで隠し層の数や、層の中のニューロンの数を加減できます。 隠し層の数を増やせばヒートマップの色分布の収束に時間がかかる様が確認できると思います。
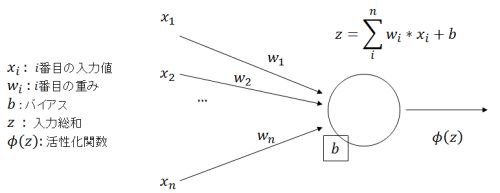
隠し層の中には1個以上のニューロンが存在します。TensorFlow Playgroundでは右に示したような四角いボックスの1つ1つがニューロンです。
ニューロンは上のシンプルな画像にあるように複数の入力値を受け取り、一つの値を出力するシンプルな計算ユニットです。
右のTensorFlow Playgroundのニューロンを見ると、四角の左側に何本かの線が見えますがこれがニューロンの入力に当たります。 四角の右側に見える線はニューロンの出力です。よく目を凝らしてみると四角の左下に似たような小さな四角がついているのが見えますが、これが ニューロンのもつバイアスです。
こうして図を見ると、ニューロンは人間が情報を認識する仕組みと似ているように思えます。 バイアス(偏見)が非常に強い人は、誰がどういうことを言っても(どんな情報を入力しても)偏見に基づいたアウトプットしかできず、 逆に偏見がなく個々の情報を総合的に判断してアウトプットする人もいます。 さらに、伝えられる情報についてどの情報が重要でどの情報が重要でないかの重みをうまくつけられるスマートな人もいるでしょう。 また、入力された情報に対して一切重みづけをせず、聞いたままを鵜呑みにして次の人に伝達する人もいますよね。
ニューロンの出力は、
入力を$\boldsymbol{x} = (x_1,x_2,...,x_i,...x_n)$、
それぞれの入力につける重みを$\boldsymbol{w} = (w_1,w_2,...,w_i,...,w_n)$、
ニューロンのバイアスを$b$、
活性化関数を$\phi$
とすると、次のように表されます。
出力$\phi = \phi\left(\displaystyle \sum_{i}^{n} \left(w_i * x_i\right) + b \right) = \phi\left( \boldsymbol{w} \cdot \boldsymbol{x} + b\right)$
活性化関数はニューロンの出力をフィルタリングする機能を持つ関数で機械学習をスタートさせる前にあらかじめどのような 関数を使うか決めておく必要があります。
TensorFlow Playgroundでは初期値は$$\phi(z) = tanh(z)$$になっています。
$tanh(z)$は単調増加な関数で値域が$(-1,1)$です。 ですので活性化関数に$tanh(z)$を選択した場合、ニューロンの入力総和が大きいほど出力も大きくなりますがニューロンの出力は-1から+1の範囲に収まります。 TensorFlow Playgroundでは他に数種類の活性化関数を選ぶことができます。活性化関数については後ほど解説します。
ニューラルネットワークの説明に戻ります。
ニューロンの出力は次の層のニューロンの入力になります。そのため層と層の間でニューロン同士がネットワークを構成しているように見えます。 このようなネットワーク層はFully-Connected Layer(FCL)と呼ばれます。
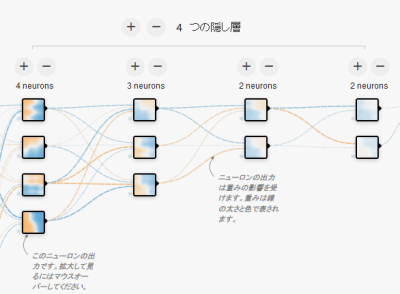
各々のニューロンの出力値はひとつだけ定まり、次の層の複数のニューロンに入力されます。 次の層のニューロンは前の層の全てのニューロンからの出力を入力値として受け取り、それぞれに重みをつけ、バイアスを加えて次の層のニューロンに渡します。
ニューロンの重み、バイアスはニューロンごとに独立しているため、同じ層に並んでいる全てのニューロンは受け取る入力値こそ同一ですが、 重みとバイアスがそれぞれ異なるため結果として各々のニューロンの出力にはニューロンそれぞれの個性が現れます。
これは上司が複数の部下から話を聞き、どの部下の話がどのくらい信用できるか評価し、部下の話とは独立した自分独自の知識(バイアス)をミックスして 次の上司に話をしに行く様と似ています。その上司は同様に、エスカレーションされた複数の話と自分の知識を総合的に判断し、さらに上へと情報を上げます。 部下の話をどう評価するか、上司自身の持つバイアスはどのくらい大きいのかによって、同じ部下から聞いた話でも上への情報の上げ方が変わってきます。
機械学習の「学習」というのは、全ニューロンの重み$w_i$、バイアス$b$を反復計算によって最適化することです。 ここでいう最適化とは、あらかじめ正解の出力が用意されたトレーニングデータを入力し 計算して得られた出力と正解の出力の誤差が最小限になるような値を探すことです。
上司と部下の例で言えば、正解を知っている社長がそれとなく一番下っ端の社員に同じ情報を渡し、その上司、さらにまたその上司 へと順々に情報が伝達された結果自分に届いた情報があらかじめ知っている正解と一致するか確かめようと する様子を想像できます。あまりにも正解と届いた情報がずれていれば、社長はその部下の取締役を叱咤し、偏見や評価のやりかたを変えるよう 促します。その取締役はその下の執行役員に、さらに執行役員は部下の部長に、といった具合にトップからボトムの方向に組織を改善しようとします。 トップからボトムへネットワークを改良しようとする計算の流れをバックプロパゲーション、(誤差逆伝搬法)と呼びます。これは後ほど説明します。
さて、機械学習の成果はこの最適化された重みとバイアスの数値の組み合わせということになります。 これらの学習済みパラメータのデータは比較的小さなサイズのファイルに収まります。 TensorFlow Playgroundでは多層パーセプトロン(MLP)という形のニューラルネットワークが採用されていますが、この場合 バイアスの数は出力層と隠し層の全ニューロンの数と一致します。重みの数については、層$l$に$k$個のニューロンが配置されている場合、重みのパラメータ数は $$ \displaystyle \sum_{l} \left( k_{l-1} * k_l \right) $$ となります。ただし$k_0$は入力層のニューロンの数とします。
例えば上記の画像のような 4-3-2-2 の構成のネットワークでは、
バイアスの数は $4+3+2+2=11$個、重みの数は$(4*3 + 2*3 + 2*2) = 22$個となります。(入力層、出力層を考慮していないため実際の数字は多少増減します)。 学習済みパラメータとしてはこの33個の数値さえあれば良いことになります。
数値1つに対して4バイト使うとしてもせいぜい100バイトのオーダーのデータサイズになります。
ここまで要約を要約します。
- ニューラルネットワークは入力層、隠し層、出力層の3種類の層から成っている
- それぞれの層にはひとつ以上のニューロンが存在する
- ニューロンは複数の入力値を受け取り、一つの出力値を返す計算ユニット
- ニューロンの出力は次の層のニューロンの入力になる
- 機械学習ではニューロンの重み、バイアスを最適化する
ニューラルネットワークについてより詳しく知りたい方は前述の参考文献をご確認ください。
ニューラルネットワークの学習に関する設定

学習率
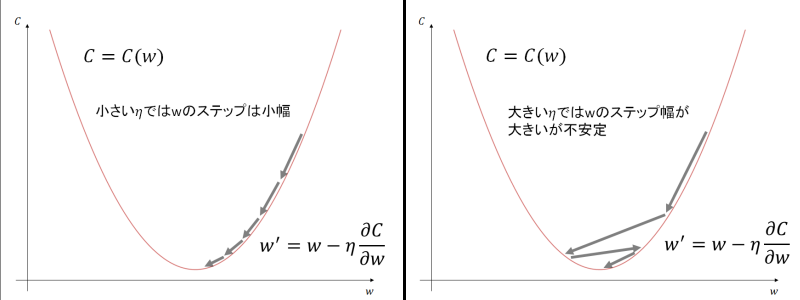
学習率は、一度の学習でどの程度重みやバイアスの値を修正するかの率を表します。 学習率が大きいと1度に修正される重み、バイアスの量が大きくなります。 小さくすると重み、バイアスの値を1度に少しだけ修正しようとします。 学習率が機械学習にどのような影響があるのか、TensorFlow Playgroundで確かめてみましょう。 初期値では学習率は0.03に設定されていますが、これを1に変えて再生(▶)ボタンをクリックしてみます。 ネットワークの重みの線の色と太さが初期値の0.03の時と比較して大きいステップで更新される様子が見られるはずです。 逆に0.0003など小さな値にして再実行してみましょう。再生(▶)ボタンの左の反時計周りの矢印ボタンで最初から再実行できます。 この場合、出力や重みの変化がほとんど見られないことが分かります。
参考文献の資料を読んだか既に機械学習についてある程度知識を持っている方であれば下記の勾配降下法の式は何度も目にしているかと思います。 初めて下記の勾配降下法の式を見る人のために式の意味を簡単に説明します。 $$ \begin{align} w' &= w - \eta \frac{\partial C}{\partial w} \tag 1\\ b' &= b - \eta \frac{\partial C}{\partial w} \tag 2 \end{align} $$ の$\eta$が学習率で、0より大きい正の値です。 $C$はコスト関数(誤差関数)で、真の出力と計算結果の出力との誤差の大きさを表す関数です。
このコスト関数の選び方は、誤差の大きさを表現できさえすれば特に決まった選び方はありませんが TensorFlow Playgroundではコスト関数は $$ C = \frac{1}{2} \left(\phi - y \right)^2 $$ としています。
$\phi$: 計算結果の出力
$y$: 真の出力
です。
$C$ をこのようにとると、真の値とニューロンの出力値に差が全く無いときに最小値0となります。
上記$(1),(2)$の式は重み $w$ および バイアス$b$を コスト関数 $C$ が小さくなるような値に更新するという意味を持ちます。 $$ \begin{align} w_{n+1} &= w_n + \alpha \\ b_{n+1} &= b_n + \beta\\ \alpha &= - \eta \frac{\partial C}{\partial w}\\ \beta &= - \eta \frac{\partial C}{\partial b} \end{align} $$ と書くとよりイメージしやすいかと思います。
$\alpha$の値がプラスかマイナスか、はたまたその量はどれくらいかによって$n+1$回目の重み・バイアスの値が変わります。 これから書く話は$w$と$b$を入れ替えても同じですので以下$w_{n+1} = w_n + \alpha$の式に絞って説明を進めます。
まずは$\alpha$の符号についてです。 $$ \alpha = - \eta \frac{\partial C}{\partial w}\\ $$ 学習率の定義より$\eta > 0$なので、 $\frac{\partial C}{\partial w}$が正であれば$\alpha$は負の値になります。 つまり、$w_{n+1}$は$w_n$よりも小さな値に更新されます。 言い換えると重み$w_n$を増やした時に誤差$C$が増えるのであれば、次回更新時の$w_{n+1}$を$w_n$よりも小さな数にすれば誤差$C$も減ることになります。
逆に重み$w_n$を増やした時に誤差$C$が減るのであれば、次回更新時の$w_{n+1}$を$w_n$よりも大きな数にすれば誤差$C$も減ることになります。
機械学習の「学習」とは、最終出力誤差$C$を最小にするような全ニューロンの重み$w$とバイアス$b$を見つけることです。ですので、$n \to n+1$の更新で $w_{n+1}$や$b_{n+1}$は誤差$C$を小さくするように値を修正しなければなりません。そのため$\frac{\partial C}{\partial w}$の符号は重要な意味を持ちます。
次は$\alpha$の量についてです。
先ほどは$\alpha$の符号について書きました。これは$w_{n+1}$を$w_n$から増やすか減らすかを判定するための条件になります。
それでは「どのくらい」増やすか減らすかはどのように制御されるのでしょうか。
ここで登場するのが学習率$\eta$です。学習率$\eta$は0より大きい正の数です。$\eta$を大きく取ると$n \to n+1$のステップ時に ステップ幅が大きくなります。逆に小さな値を取るとステップ幅が小刻みになります。
ステップ幅が小さいと小刻みに$w$の値が修正されていきますが、そのため誤差$C$が0に近づくまでにたくさんの時間を要します。 ステップ幅が大きいと$C$が0に近づく勢いは強いですが、勢いがありすぎて$C = 0$を飛び越してしまうことが頻発します。 最適な学習率はどのくらいなのかは難しい質問です。 直感的には、誤差$C$が大きい時には$\eta$を大きくし、$C$が十分に小さくなったあとは$\eta$を小さな値にして微修正をして誤差0に近づける、 といった方法もありそうです。 私が調べた範囲では機械学習を始める前から「これがベストな学習率$\eta$の値だ」と決められるものではないようです。
活性化関数
活性化関数はニューロンの出力をフィルタリングします。 ニューロンは上図の通り一つ前の層のニューロンの出力の総和を重み・バイアスを元に計算し、それを活性化関数に通して出力値を確定します。 $$ \phi = \phi(z) = \phi\left( \sum_{i} \left(\ w_i x_i \right) + b \right) $$ TensorFlow Playgroundでは$\phi$の初期値としてtanhが設定されています。
他にもReLU, シグモイド関数、線形関数の選択肢があります。
| グラフ | 活性化関数 | 式 | 値域 | 導関数 |
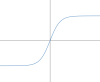 | $tanh(z)$ | $$\phi(z)=\frac{e^{-z} - e^z}{e^{-z} + e^z}$$ | $(-1,1)$ | $\phi'(z)=1-\phi^2(z)$ |
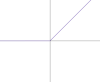 | $ReLU(z)$ | $$\phi(z)=\frac{1}{2} \left(|z| + z\right)$$ | $[0,\infty)$ | $\phi '(z)=\begin{cases} 1, & \text{for $z$ ≥ 0 } \\ 0, & \text{for $z$ < 0 } \end{cases}\\$ |
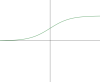 | $sigmoid(z)$ | $$\phi(z)=\frac{1}{1+e^{-z}}$$ | $(0,1)$ | $\phi'(z)=\phi (z) \cdot \left(1 - \phi (z)\right)$ |
 | $Linear(z)$ | $$\phi(z)=z$$ | $(-\infty,\infty)$ | $1$ |
活性化関数は、Wiki - Activation function にあるように様々な選び方があります。活性化関数自体の形以外に、活性化関数の導関数も活性化関数を決める重要なファクターです。 詳しくはバックプロパゲーションの項に書きます。
正則化、正則化項
正則化を理解するためには、まず過学習(over-fitting)について知る必要があります。
ダーツの学習用データ(トレーニングデータ)を使って十分に訓練したニューラルネットワークがあるとします。 トレーニングデータについて、ニューラルネットワークの計算結果の出力と真の出力と誤差が十分ゼロに近づいたので、 あなたは未知の座標$(x,y)$について出力の得点$f(x,y)$が十分な精度で予測できるだろうと考えました。 試しに適当な座標$(x',y')$にダーツを投げたら得点はどうなるかニューラルネットワークに問い合わせてみました。
すると、客観的に見て明らかに誤った得点が返答されました。十分に学習させたはずのニューラルネットワークなのに何故…。 これが過学習です。トレーニングデータに対してのみネットワークのパラメータ(重み、バイアス)が最適化されているので、 トレーニングデータに"似ていない"新しいデータを入力したときに、誤った出力をネットワークが返してしまう問題です。
これは世論調査などの統計でも想像しやすい話です。アイドルの好感度調査をする際に、アイドルのライブイベント会場でアンケートをとると いくら大量の回答を集計したとしても、"世間一般"のアイドルの好感度とはフィットしない統計結果が生まれる可能性が高くなります。
TensorFlow Playgroundで意図的に過学習を起こすことは簡単です。
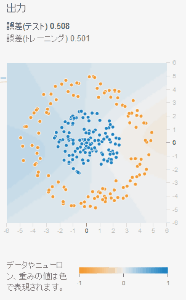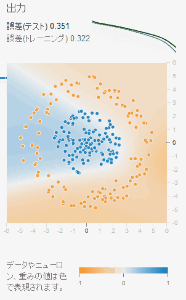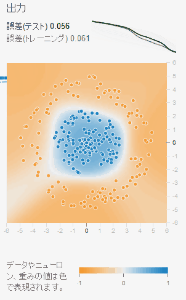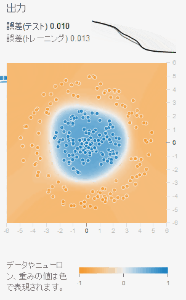
画面左側の「トレーニングデータの割合」を10%まで下げてみましょう。ちなみにトレーニングデータとテストデータについてはここで説明しています。 簡単にいうとトレーニングデータの割合を10%にすると、入力に対して答えの出力が分かっているデータの10%をトレーニングデータにまわし、 残りの90%をテストデータに回すことになります。トレーニングデータは重み$w$やバイアス$b$を修正するために使われますが、 テストデータは重みやバイアスを修正せず、誤差を計算するためだけに使われます。
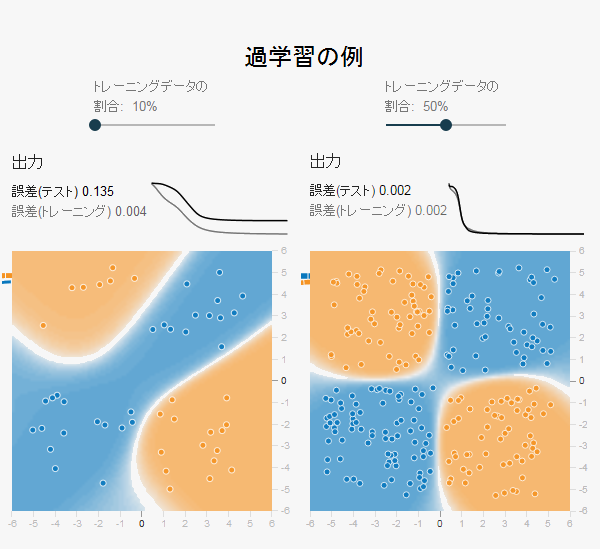
上図はトレーニングデータの割合を10%にしたものと50%にしたものでのTensorFlow Playgroundの出力結果の違いです。 2つともトレーニングデータの誤差についてはほぼ0に近い数字になっていますが、トレーニングデータの割合が10%のものは テストデータの誤差が非常に高く、ヒートマップも不自然な形になっています。 これはトレーニングデータのみにフィットするようニューラルネットワークがパラメータを調整した結果です。
過学習が発生すると、十分に小さなトレーニングデータの誤差に対して、テストデータの誤差が小さくならない現象が発生します。 上図の左を見れば、トレーニングデータのオレンジ・ブルーの点の分布とヒートマップの分布は確かに間違ってはいないことが分かります。
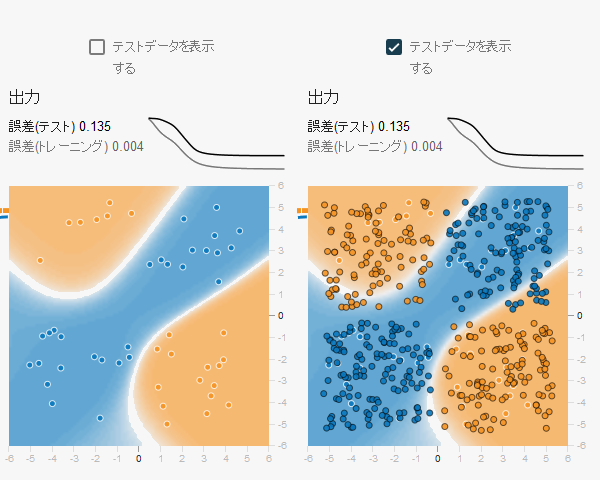
上の図ではテストデータが表示されたヒートマップを並べてみました。右の枠の色が濃い点々がテストデータです。 トレーニングデータについては色の分布がきちんとフィットしていますが、学習に使っていないテストデータで誤差を確かめると かなりズレがあることが分かります。
過学習が機械学習で問題になるのは、トレーニングデータの誤差が十分に0に近づいてしまうとニューロンの重みやバイアスが それ以上ほとんど更新されなくなってしまうことです。
機械学習ではトレーニングデータの誤差$C$を小さくするように重み$w$とバイアス$b$を反復修正しますが、 誤差$C$が十分小さくなると学習率の欄で説明した $$ \frac{\partial C}{\partial w} ,\, \frac{\partial C}{\partial b} $$ の値が小さくなります。つまり $$ w' - w = -\eta \frac{\partial C}{\partial w} \to 0\\ b' - b = -\eta \frac{\partial C}{\partial b} \to 0 $$ となり、これ以上学習が進まなくなってしまうのです。
それでは過学習を防ぐためにはどうすればよいでしょうか。
すぐに思いつくのはトレーニングデータの数を増やすこと、データの偏りが無いように注意を払うことです。 しかしこれらをしなくとも、過学習を防ぐための仕組みがあります。
それが正則化(Regularization)と呼ばれるテクニックです。
TensorFlow Playgroundでは2つの正則化方式を選択できます。L2正則化とL1正則化です。
L2正則化もL1正則化も誤差関数$C$に正則化項を加えるだけのシンプルなオペレーションです。
L2正則化: $$ C' = C_0 + \frac{\lambda}{2 n} \sum_{w_i \in all} w_{i}^2 $$ L1正則化: $$ C' = C_0 + \frac{\lambda}{n} \sum_{w_i \in all} |w_i| $$ ここで、$C_0$はオリジナルの誤差関数です。TensorFlow Playgroundでは $C_0 = \frac{1}{2}\left( \phi - y \right)^2$ となっています。
$\lambda$は正則化項の大きさをスケールさせる係数で、$\lambda \gt 0$です。TensorFlow Playgroundでは0から10までの値が設定可能です。 $\lambda$を0にすると正則化項が存在しないものと同じことになります。($\lambda=0$を選択できるようにしている理由は私はよく分かりません)。 $\lambda$の値を大きくすると誤差関数における正則化項の影響が大きくなります。
$n$はトレーニングデータのサンプル数であることが多いようですが、TensorFlow Playgroundでは$\lambda$の中に含めているようで$n$は 計算に出てきませんでした。
正則化されたニューラルネットワークではこの正則化項を加えた修正誤差関数$C'$を小さくする重み$w$およびバイアス$b$を求めることになります。
さて、それでは何故正則化が過学習の防止に役立つのでしょうか。
正値($>0$)の正則化項を足したことで、誤差関数$C$はこれまでより$0$になりにくくなったことが分かります。 直感的には常にニューラルネットワークに曖昧さを残しておく機能があるように思えます。 どんなに勉強をしても「もう全て知ってしまったのでこれ以上勉強する必要はない」と思わず 「まだまだ自分には知らないことがある」と考えるようなものです。
L2正則化を例により詳しく見てみましょう。 $$ C' = C_0 + C_{\text{reg}}\\ C_{\text{reg}} := \frac{\lambda}{2 n} \sum_{w_i \in all} w_{i}^2 $$ 重み$w_i$の数はニューロンの数を増やせば増やすほど増えますが、ここでは簡単のため重みが2つしかないニューラルネットワークを 考えてみましょう。下の図を見てください。
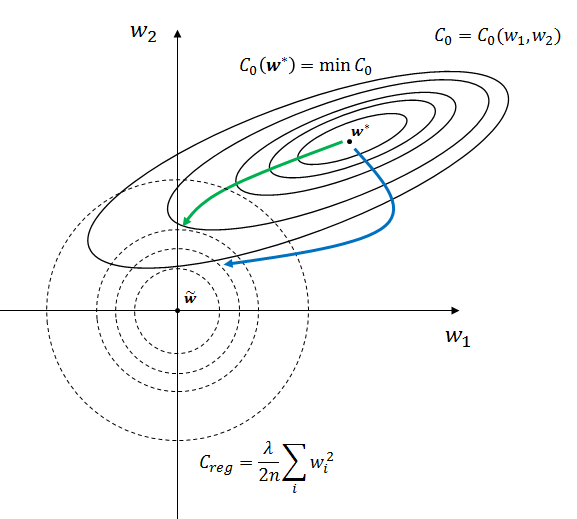
この図は2つしかない重みについての2次元平面です。重みが3つの時を考える場合はこれが3次元空間に、n個の重みを考えるときは n次元空間になるのですが、4次元空間や5次元空間を図示するのは難しいので簡単のため今回は重みが$w_1$と$w_2$の2つしかない 2次元空間で話をします。
図の$\mathbb{w}^*$というのはオリジナルの誤差関数$C_0$を極小にする極値点です。 言い換えると $$ \frac{\partial C(\mathbb{w}^*)}{\partial \mathbb{w}} = 0 $$ となる点$\mathbb{w}^*$のことです。
過学習は重み$\mathbb{w}$が$\mathbb{w}^*$に落ち込んだ時に発生します。誤差$\dfrac{\partial C_0}{\partial w}$が$0$になってしまっているので $$w' = w - \eta \frac{\partial C}{\partial w} \to w$$ となり$w'$がほとんど修正されなくなります。
そこで過学習を防ぐため正則化項 $C_{\text{reg}}$を誤差関数に加え、 $$ C' = C_0 + C_{\text{reg}} $$ とします。
L2正則化では $$ C_{\text{reg}} = C_{\text{reg}}(w_1,w_2) = \frac{\lambda}{2 n} \sum_{i \in \{1,2\}} w_{i}^2 = \frac{\lambda}{2 n} (w_{1}^{2} + w_{2}^{2}) $$ となります。
$C_{\text{reg}}(w_1,w_2)$は $w_1 = w_2 = 0$の時最小値を取ります。また、$f(x,y) = x^2 + y^2$の形の関数の値は 中心0の円の半径 $\sqrt{x^2+y^2}$ の大きさと一致します。上の図の点線の円の大きさは $w_1,w_2$ 平面上の $C_{\text{reg}}$ の大きさを表しています。 上図中では $\tilde{\mathbb{w}}$ が$C_{\text{reg}}$ を最小にする点となります。
$C_0$ についても同様に実線の等高線で座標$(w_1,w_2)$における$C_0$の大きさを表現するようにします。 $C_0$の関数形は特定できないですが、ここでは楕円のような形の等高線にしてみます。 これは楕円の円周に沿って重みベクトル$\mathbb{w}$を動かせば$C_0$は変わらないことを意味します。 楕円の長軸方向に沿って$\mathbb{w}$を動かすと$C_0$の変化はなだらかです。 短軸方向に$\mathbb{w}$を動かすと$C_0$は急激に変化します。
仮に$C{\text{reg}}$を考えず、重みが数々の学習を乗り越えて $\mathbb{w} = \mathbb{w^*}$に到達し、 $C_0$が最小値をとってしまった後のことを考えます。
$$ C' = C_0(\mathbb{w_*}) $$ です。この時、重み$w$で偏微分しても点$\mathbb{w_*}$上では微分値は$0$になります。 この状態で上式に $C_{\text{reg}}$ を足してみましょう。 $$ C' = C_0(\mathbb{w_*}) + C_{\text{reg}} = C_0(\mathbb{w_*}) + \frac{\lambda}{2 n} (w_{1}^{2} + w_{2}^{2}) $$ さて、どのように重み$\mathbb{w}$を動かせばトータルの誤差$C'$を小さくできると思いますか?
それは図を見れば明らかです。
正則化項 $\dfrac{\lambda}{2 n} (w_{1}^{2} + w_{2}^{2})$が加わったことで重みベクトル$\mathbb{w}$が原点から遠ければ遠いほど 誤差が大きくなっています。この誤差を小さくするためには$\mathbb{w^*}$に安寧して留まっている重みベクトル$\mathbb{w}$を引っ張りだして 原点方向に移動させなければなりません。 しかしだからといって原点まで $\mathbb{w}$ を持ってきてしまうと今度は$\mathbb{w^*}$ から離れすぎているため$C_0$の値が 大きくなってしまいます。つまり正則化誤差$C'$を最小にする$\mathbb{w}$は$\mathbb{\tilde{w}}$と$\mathbb{w^*}$間の中間に存在することになります。
また、$\mathbb{w}$ を$\mathbb{w^*}$から一直線に原点の近くまで動かせば良いものでもありません。 上図の実線の等高線を見ると分かる通り、誤差$C_0$の勾配ががなだらかな経路(緑色の線)と急な経路(青色の線)があります。
オリジナル誤差$C_0$については点$\mathbb{w^*}$から等高線をまたげばまたぐほど値が大きくなってしまうため、 $C_0$の値を抑えたまま$C_{\text{reg}}$を小さくするためにはなだらかな緑の線に沿って重みベクトル$w$を移動させる 必要があります。補正誤差$C'$を最小にする点は点線と実線の等高線の交点上に存在します。
点$\mathbb{\tilde{w}}$と点$\mathbb{w^*}$のどちらに重みベクトル$\mathbb{w}$を寄せるかは正則化項のパラメータ$\lambda$で調整をします。
このように、正則化項を加えるとトレーニングデータのみで学習したネットワークに一定量の疑いを差し挟むことになります。 どのくらいトレーニングデータを疑うかの度合いを正則化項のパラメータ$\lambda$で指定するのです。
統計モデルの種類

TensorFlow Playgroundの画面右上に統計モデルの種類(英語版ではProblem Type)という設定項目があります。初期値は"分類"となっています。
"分類"では上記のダーツの説明でいう得点の値が-1もしくは1の2通りの離散的な値のみとなります。-1,1の間の0.4や-0.8345などの値はありません。
入力した画像が猫であるか猫でないかを0/1で判断するのが分類になります。
もうひとつ"回帰"という設定値もあります。こちらは得点の値について-1,1だけのとびとびの離散的な値だけでなく、 その間の-0.529や0.29039などの-1から+1までの連続的な中間値も考慮に入れます。
入力した画像が猫である確率を求める場合はこちらになります。
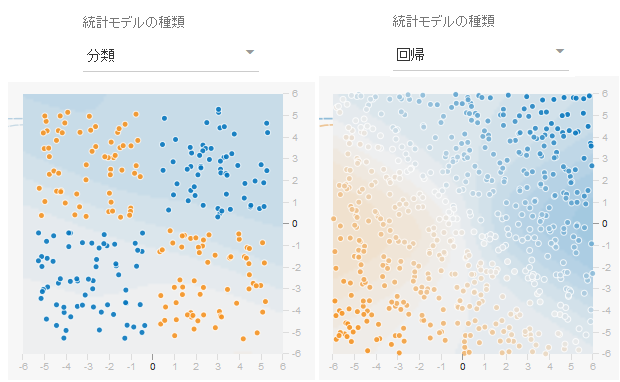
左の"分類"の図は点々がブルー(+1)かオレンジ(-1)かの二通りの出力結果のデータの分布です。 対して右の"回帰"の図は+1の点がブルー、-1の点がオレンジであることには変わりありませんが 白味がかった-1と+1の間の中間の値のデータも含まれています。
データに関する設定
どのデータセットを使うか
TensorFlow Playgroundでは統計モデルの種類が"分類"で4種類、"回帰"で2種類学習させたい分布を選択できます。
これが機械学習で推測させる真の分布です。
排他ORやガウシアンなどのシンプルな分布は何となく容易に分布を推測できそうですが、螺旋分布は正確に分布を当てるのは難しそうです。
TensorFlow Playgroundのヒートマップの平面の目盛りを見れば分かる通り、座標 $x,y$ の定義域は$[-6,6]$です。
また、座標$(x,y)$における出力値$f(x,y)$の値域は分類で$f \in \{-1,1\}$、回帰で$f\in [-1,1]$です。
TensorFlow Playgroundで用意されている真の分布について下記の表に特徴をまとめました。
| グラフ | 名前 | 式 | 説明 | |
| 分類 |  | 円 | $$f(x,y) = \begin{cases}+1; \quad x^2 + y^2 < 2.5^2\\ -1; \quad x^2 + y^2 ≥ 2.5^2 \end{cases}$$ | 半径2.5の円の内側で+1、外側で-1。ブルーの点のトレーニングデータは半径 $r\in[0,2.5]$、偏角 $\theta\in[0,2\pi)$ からランダムに、オレンジのデータは半径 $r\in[3.5,5]$、偏角 $\theta\in[0,2\pi)$ からランダムに選んで生成される。 |
 | 排他OR(XOR) | $$f(x,y) = \begin{cases}+1;\quad x y ≥ 0\\-1;\quad x y < 0 \end{cases}$$ | $x,y$の符号が同じなら+1、異なるなら-1。$x$も$y$も点の座標は完全にランダムで生成される。 | |
 | ガウシアン | $$f(x,y) = \begin{cases}+1; \quad x,y \in N(+2, \text{noise})\\-1; \quad x,y \in N(-2, \text{noise}) \end{cases}$$ | $N(\mu,\sigma^2)$は平均$\mu$、分散$\sigma^2$の正規分布とする。$x,y$の座標が $\mu=2$、$\sigma^2=$ノイズ(*後述)の正規分布に従う場合+1、$\mu=-2$の正規分布に従う場合-1としている。$x,y$座標は全データサンプルの内半分を前者の正規分布に、残り半分を後者の正規分布に従うよう生成している。 | |
 | 螺旋 | $$ \begin{align} \text{Define: } & x=r \sin(\theta),\\& y= r \cos(\theta),\\& r = 5 t,\\& \theta = 1.75 \cdot 2 \pi t + \theta_0 \end{align} $$ $$ f(x,y) = g(t, \theta_0) = \begin{cases} +1;\quad \theta_0 = 0\\ -1;\quad \theta_0 = \pi \end{cases} $$ | 偏角 $\theta$が増えるに従い半径も増加する螺旋関数。$t \in [0,1]$。全データサンプルの数を$N$とすると、$t_0=0$から$t_{\frac{N}{2}-1}=1$までの$\frac{N}{2}$個の$t$について+1となる点と-1となる点の座標$(x,y)$をそれぞれ生成する。2つの$\frac{N}{2}$ 個のデータサンプルの組の内、 $\theta_0 = 0$の組を+1の点の組、$\theta_0 = \pi$の組を-1の点の組とする。 | |
| 回帰 |  | 線形 | $$f(x,y) = \frac{x + y}{10}$$ | $x$と$y$の値が両方大きければ$f(x,y)$の値は大きく、両方小さければ$f(x,y)$は小さくなる。$f>1$となる$f$については全て$1$としてカウントする。$f<-1$となる$f$についても同様に$-1$とする。 |
 | マルチガウシアン | $$ f(x,y) = f(\boldsymbol{x}) = sign * (1 - \frac{D(\boldsymbol{x})}{2}) $$ $$ \boldsymbol{x} = (x,y) $$ $$ D(\boldsymbol{x}) = \min_i |\boldsymbol{\mu}_i - \boldsymbol{x}| $$ $$ \boldsymbol{\mu}_i = \begin{cases} \begin{align} (-4,\, 2.5); \quad &i=1\\ (0,\, 2.5); \quad &i=2\\ (4,\, 2.5); \quad &i=3\\ (-4,\, -2.5); \quad &i=4\\ (0,\, -2.5); \quad &i=5\\ (4,\, -2.5); \quad &i=6 \end{align} \end{cases} $$ $$ sign = \begin{cases} \begin{align} 1;\, &D(\boldsymbol{x}) \text{ で選ばれる } i \text{ が奇数}\\ -1;\, &D(\boldsymbol{x}) \text{ で選ばれる } i \text{ が偶数} \end{align} \end{cases} $$ | $x,y$座標上の6つの点 $\boldsymbol{\mu}_i$ について、それぞれの点の近傍で$f(x,y)$の絶対値が大きくなる。 $f(x,y)$の符号は$(x,y)$から最も近い$\boldsymbol{\mu_i}$がどれかによって決まる。 これら6つの点のどの点からも離れている座標$(x,y)$では$f(x,y)$の絶対値が小さくなる。 また $D(\boldsymbol{x})$の上限は$2$とし、$D > 2$となる$D$については$D=2$と置き換える。 |
トレーニングデータの割合
TensorFlow Playgroundで学習に用いるデータのサンプル数は"分類"で500個、"回帰"で1200個です。
データサンプルは $(x,y,f(x,y))$ の値の組み合わせです。これが500もしくは1200個用意されます。
これら数百以上のサンプルを用いてネットワークを学習させるのですが、全てのデータを学習に回すわけではありません。
学習され鍛えられたネットワークが本当に正しく学習しているか、誤った方向に学習していないかテストするためのデータサンプルが必要になります。
学習に使うデータサンプルをトレーニングデータ、テストに使うデータサンプルをテストデータと呼びます。
テストデータというからには当然入力に対する正しい答えがあらかじめ分かっているデータでなければなりません。
つまりテストデータはトレーニングデータと区別できない同じデータサンプルを使います。
TensorFlow Playgroundでは上図のように数百個のデータサンプルのうち何割をトレーニングデータに回し何割をテストデータに回すか設定できます。 例えばトレーニングデータの割合を60%とすると、上記の例では500個のデータサンプルの内300個をトレーニングデータに、 200個のデータをテストデータに回します。
このように、サンプルデータを分割してトレーニングデータとテストデータに分けて学習の妥当性を検証することを交差検証と呼びます。
ノイズ

ここで設定できるノイズとは、円やガウシアンなどの選択したデータセットに対してかけるノイズです。 TensorFlow Playground上の画面からはノイズは0〜50まで5刻みで設定できますが、 どのようにノイズをかけるかは選択したデータセットによって変わります。 ちなみにノイズの数値は%単位です。 ガウシアンの分布生成時に分散の値としてノイズを使っていますが、画面上からノイズを50と設定した場合、 分散の値としては0.5が使われます。
バッチサイズ
batch: 1束の、1回分の、ひとまとまりの数
バッチサイズは1回の学習(重み、バイアスの更新)を何個のトレーニングデータで実施するかを決める数値です。
例えばバッチサイズを1とすると、トレーニングデータを1つニューラルネットワークに入れるたびに全ニューロンの重み、バイアス を更新しますが、バッチサイズを10とすると10個のトレーニングデータにつき1回パラメータを更新します。
ちなみに、TensorFlow Playgroundではエポック(Epoch)というカウンタがあります。
用意された全トレーニングデータをニューラルネットワークに投入しパラメータを更新、修正し終えると機械学習の1サイクル(1エポック)が完了します。 統計モデルの種類が分類の場合、トレーニングデータは500個なので、この500個全部をトレーニングに使い切ると1エポック完了したことになります。 バッチサイズが1の場合、1つのトレーニングデータにつき一回学習(パラメータの更新)をしますので、1エポックで500回学習することになります。 バッチサイズが25の場合は1エポックで20回学習することになります。
これまで誤差関数$C$を $$ C = \frac{1}{2} \left( \phi - y \right)^2 $$ と書いてきました。これはトレーニングデータ全体の中の一つのトレーニングデータの真の出力と計算出力の誤差を表します。
実際は全てのトレーニングデータに対して一つの誤差関数を下記のように定めます。 $$ C = \frac{1}{n} \sum_{\boldsymbol{x}} C_{\boldsymbol{x}} $$ ここで$C_{\boldsymbol{x}}$は、ある1つのトレーニングデータで計算される誤差関数の値で、 $$ C_{\boldsymbol{x}} = \frac{1}{2} \left( \phi(\boldsymbol x) - y \right)^2 $$ です。
$n$はトレーニングデータの数です。TensorFlow Playgroundでは統計の種類が分類の時はトレーニングデータは500個用意されているので $n=500$、回帰の時は1200個のトレーニングデータが用意されているので$n=1200$となっています。
トレーニングデータ全体の誤差は個々のトレーニングデータの誤差の平均です。
そのため、勾配降下法で利用する重みやバイアスの補正項はより一般化して書くと $$ \frac{\partial C}{\partial w} = \frac{1}{n} \sum_{\boldsymbol{x}} \frac{\partial C_{\boldsymbol{x}}}{\partial w},\quad \frac{\partial C}{\partial b} = \frac{1}{n} \sum_{\boldsymbol{x}} \frac{\partial C_{\boldsymbol{x}}}{\partial b} $$ となります。この時、重み$w$、バイアス$b$の勾配降下法の式は $$ w' = w - \frac{\eta}{n} \sum_{\boldsymbol{x}} \frac{\partial C_{\boldsymbol{x}}}{\partial w} \\ b' = b - \frac{\eta}{n} \sum_{\boldsymbol{x}} \frac{\partial C_{\boldsymbol{x}}}{\partial b} $$ と書けます。
この式は新たな重み、バイアスを求めるには全てのトレーニングデータについて $\partial C / \partial w$、$\partial C / \partial b$を計算し、 それを$n$で割って平均をとる必要があると言っています。このやり方はトレーニングデータ全体に対する誤差を小さくすることを目的にしていますが、 全トレーニングデータを使った機械学習1エポックあたり1度しかパラメータを更新しないので、学習速度が非常に遅くなります。
そこで$m = \{m\,|\,1≤m≤n,\,m \in \mathbb{N}\}$となるバッチサイズ$m$を決め、全部のトレーニングデータから $m$個のトレーニングデータをランダムにピックアップし、この$m$個のトレーニングデータについて$C_{\boldsymbol{x}}$の 平均を取りそれを使って重み・バイアスを補正するという方法を考えます。 トレーニングデータ全てのデータから誤差を計算して平均を取ることと、 その中の一部のランダムなm個の誤差の平均を取るのでは大体結果は同じようなものになるだろうという仮定をおいています。 $$ \frac{1}{m} \sum^{m}_{k=1} C_{X_{k}} \approx \frac{1}{n} \sum_{\boldsymbol{x}} C_{\boldsymbol{x}} $$ このようにランダムに$m$個のトレーニングデータをピックアップし勾配降下を計算する方法を確率的勾配降下法(stochastic gradient descent)と呼び、 ピックアップされた$m$個のトレーニングデータはミニバッチ(mini-batch)と呼びます。$m=n$の場合は一部ではなく全トレーニングデータの束で、 バッチ(batch)と呼びます。 全部で$n$個のトレーニングデータから$m$個のミニバッチを重複の無いよう繰り返し取り出してネットワークを更新し、 全てのトレーニングデータでトレーニングが終わるとそこで1エポック終わったことになります。
ちなみにTensorFlow Playgroundの実装では、エポック毎にトレーニングデータをランダムにシャッフルして並び替え、 先頭から順々に$m$個ずつトレーニングデータを取り出して機械学習させています。
入力するデータの特徴と隠し層

まず、入力の特徴(feature)について説明します。
特徴というのは、入力データを表す代表的な値のことです。その値の大きさを特徴量と呼びます。
TensorFlow Playgroundでは座標$x,y$が入力データの特徴ということができます。(後ほど説明しますが、$x,y$のみが特徴になるわけではありません。) これがMNISTの手書き文字であれば各ピクセルの位置とそのピクセルのグレースケールの値を特徴としてとらえることができます。 例えば、30番目のピクセルの色の濃さは200だ、と言った具合です。
いずれの特徴も直接的もしくは間接的に数値で表現できる必要があります。
「車」の特徴について考えてみましょう。車を表す特徴はいくつか想像できます。例えば車の値段、車高、車幅、最高速度、 燃費、色、窓の大きさ、ドアの数、などなど様々な特徴が簡単に思いつきます。
ここで、あなたは自動車メーカーの製品企画部の社員で、新車開発に際して売れる車のコンセプトの提案を求められたとします。 あなたはこれまでに発売された全メーカーの全車種に関するスペックデータ、販売結果のデータなど分析に必要なデータを持っています。 この状態で機械学習のモデルを作るとしましょう。 入力は上に上げた車の特徴になります。そして出力はその車の売上総額とすれば良いとすぐに思いつきます。
しかしここで問題があります。ひとえに「車の特徴」と言っても特徴の数が多すぎてどれを入力に使えばいいか簡単には判断できないのです。 例えばデータとして「エアバッグの布の重さは何グラムか」とか「タイヤのボルトの大きさは何ミリか」など「自動車で使われている部品点数」 などの特徴は販売結果にあまり大きな影響はなさそうです。
機械学習を始める前に出力結果に影響を与えそうな入力データの特徴を取捨選択するプロセスは Feature Engineeringと呼ばれます。Feature Engineering自体、多くの研究者の興味の対象になっている非常に重要なプロセスです。 Deep Learning登場以前は、こういった「どの特徴を機械学習の入力に用いれば良いか」はその道のエキスパートにしか うまく判断できませんでした。
しかし近年のコンピュータの計算能力の進化やDeep Learningの登場によって、Feature Engineeringを ネットワークに自動で行わせることができるようになりました。つまり、シンプルにありとあらゆるデータを入力すれば、 ニューラルネットワークが自動でデータの特徴を見つけてくれるのです。
ニューラルネットワークが自動で特徴を発見してくれるとはいえ、モデルの推計にインパクトのある適切な特徴を選択するプロセスは 現在でも重要です。モデルをうまく表す良い特徴を入力とすれば機械学習の精度やスピードはかなり高まります。 不要な特徴を含んだ入力データで機械学習をしようとすると、非常に大きな数の学習サンプルが必要になってしまうため ある程度人力での特徴選択は現在でも必要です。
TensorFlow Playgroundでは単純な座標$x,y$だけでなく様々な特徴を入力として選択できるようにしています。
 | $$i_x=x$$ |  | $$i_y=y$$ |
 | $$i_{x^2}=x^2$$ | 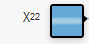 | $$i_{y^2}=y^2$$ |
 | $$i_{xy}=xy$$ |  | $$i_{\sin x}=\sin x$$ |
 | $$i_{\sin y}=\sin y$$ |
TensorFlow Playgroundでは入力する特徴を一つまたは複数選択できます。例えば、単純に座標$(x,y)$を入力とする場合は、 $i_x=x$の特徴と$i_y=y$の特徴を2つ選択すれば実現できます。
これは次の層に入力される入力層のニューロンの出力が $$w_1 \cdot i_x + w_2 \cdot i_y = w_1 x + w_2 y$$ となり、結果的に下記のように$x$, $y$のニューロンを2つ置くことと同義になっているからです。
特徴の選択はどのようにすれば良いのでしょうか。これもTensorFlow Playgroundで学べる重要な事柄です。 シンプルに書くと、出力のモデルをうまく説明できるような特徴を選択すれば良いのです。
例えばその増減が出力のモデルに直接影響を与えると考えられるような特徴です。
実際のところ、ニューラルネットワークでは驚くべきことに与えられたデータから特徴を自動で抽出してくれます。 ちなみに、入力層と出力層を含んだ3層以上のニューラルネットワークのことをディープニューラルネットワーク(DNN)と 呼びます。層やニューロンの数が増えるほど柔軟に特徴を抽出することができます。
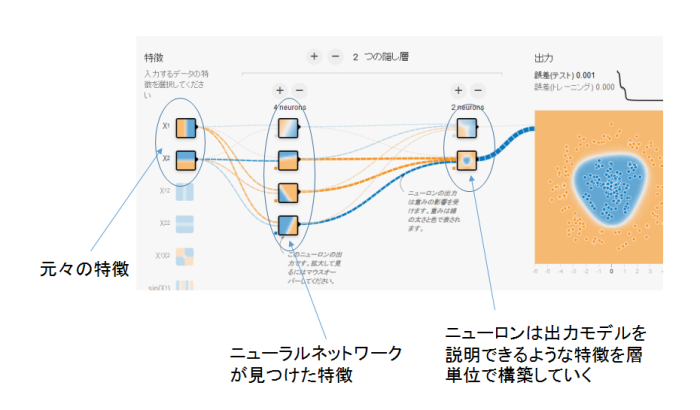
上の図で入力層の特徴は$i_x = x,\, i_y = y$が選択されています。
また、データセットは円のモデルです。 隠し層の第一層目のニューロンを見てみましょう。これらのニューロンにヒートマップが表示されていますが これはネットワークに$x,y$を与えた時、ニューロンの出力がどのように分布するかを表しています。途中出力のようなイメージです。 1層目のニューロンではオレンジとブルーの点が直線で分けられています。それぞれのニューロンは直線の傾きが異なるだけのように見えます。
この時の隠し層第一層目のニューロンの出力を数式で見てみましょう。 $$ \text{output} = \phi (z) = \phi \left( w^{1}_{1,i} x + w^{1}_{2,i} y + b^{1}_{i} \right) $$ ただし、$w^{l}_{j,i}$は層$l$の$i$番目のニューロンが前の層の$j$番目のニューロンにかける重み、 $b^{l}_{i}$は層$l$の$i$番目のニューロンのバイアスとします。 また、活性化関数$\phi$は$\phi(z) = \tanh(z)$とします。
ここで$\tanh(z)$は単調増加な関数で下記に示したような形状をしています。
| グラフ | 活性化関数 | 式 | 値域 | 導関数 |
| $tanh(z)$ | $$\phi(z)=\frac{e^{-z} - e^z}{e^{-z} + e^z}$$ | $(-1,1)$ | $\phi'(z)=1-\phi^2(z)$ |
グラフの形状を見れば分かる通り$z=0$で$\tanh(z)=0$、$z>0$で$0< \tanh(z) < 1$、$z < 0$なら$-1 < \tanh(z) < 0$となっています。 ニューロンのヒートマップは出力が0より大きい時にブルー、小さい時にオレンジになります。 ここでブルーとオレンジの点を分ける白の線は$\phi(z) = 0$、つまり$z=0$となる$(x,y)$です。 $$ z = w^{l}_{1,i} x + w^{l}_{2,i} y + b^{l}_i = 0 $$ です。上記の$w x + w' y + b = 0$を満たす線は直線であることが分かります。
これが上記図の隠し層の第一層目のニューロンのヒートマップが直線となっている理由です。 直線の傾きは$w^{l}_{j,i}$の数値によって制御されます。また$b^{l}_{i}$は直線を平行移動させる役割を持ちます。
もうひとつ注目すべきことがあります。第一層目のニューロンの出力を表す式 $$ \tanh(w^{l}_{1,i} x + w^{l}_{2,i} y + b^{l}_{i}) $$ ですが、これは入力の特徴としてそっくりそのまま使えてしまうのです。
もちろん重み$w$とバイアス$b$の値は決めておく必要があります。例えば入力する特徴を下記のようにすれば良いのです。 $$ i_{\tanh} = \tanh(3x + 2y + 1) $$ ただ、$\tanh$をそのまま特徴として 入力層に持ってきても特に面白いことはありません。
上のスクリーンショットの隠し層第二層目のニューロンを見てみましょう。
この2つのニューロンは下記の数式の産物です。 $$ \begin{align} \text{output}^{2}_{i} &= \tanh \left( \sum_k \left( w^{2}_{k,i} \tanh(w^{1}_{k,i} x + w^{1}_{k,i} y + b^{1}_k) \right) + b^{2}_{i} \right)\\ &= \tanh \left( w^{2}_{1,i} \tanh(w^{1}_{1,i} x + w^{1}_{1,i} y + b^{1}_1) + w^{2}_{2,i} \tanh(w^{1}_{2,i} x + w^{1}_{2,i} y + b^{1}_2) + ... + b^{2}_{i} \right) \end{align} $$ 重みとバイアスのパラメータが少し違うだけで、同じ層のニューロンなのにヒートマップの形状がここまで異なるのも面白いですね。
図を見ると2番目のニューロンのほうが出力層のニューロンにつながる線が太いことが分かります。 これは2番目のニューロンの線が出力に寄与する度合いが大きいことを示しています。
さて、さきほど隠し層のニューロンの出力は特徴として見ることができると書きました。 そして良い特徴の選び方は出力をうまく説明する特徴だということも書きました。 ここでこの2番目のニューロンの形を見てみましょう。座標が原点に近いほど出力が大きいことが分かります。また、原点から離れるに従って 出力が小さくなる様子も見れます。 2次元平面上で原点に近いほど値が大きく、原点から離れるほど値が小さくなる特徴はどのように表現できるでしょうか。 私は下記のような特徴を考えました。 $$ \text{input} = -(x^2 + y^2) + 1 $$ です。$x = y = 0$で最大値$1$を取り、原点から離れるに従って値がマイナス方向に小さくなっていきます。 上のスクリーンショットでは$i_x = x$および$i_y = y$の2つの特徴を選択しました。 ですが、今回の隠し層のニューロンの出力を観察することで、より良い特徴は$i_{x^2}=x^2$と$i_{y^2}=y^2$であることが言えます。
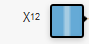
試しにTensorFlow Playgroundで円のデータセットを選択し、$X^1$と$X^2$の2つの特徴を選択した状態で機械学習させた時の速さと、 $X^{12}$、$X^{22}$の2つの特徴を選択したときの速さを比べてみれば、その違いが体感できると思います。
良い特徴を選ぶことの重要性が理解できる例です。
バックプロパゲーション(誤差逆伝搬法)
機械学習では誤差を最小にする重み$w_i$と$b$を探しますが、ここではその探し方について説明します。 バックプロパゲーションはその名の通り、最後の出力層から始まり最初の入力層に向けてトップダウンにパラメータ( $w_i,b$ )を修正します。 バックプロパゲーションに対してフォワードプロパゲーションという言葉もあります。 これは入力層から出力層まで層単位で順々にニューロンを通り最後に出力層に入力値が伝搬する 通常のボトムアップ型のニューラルネットワークの計算です。
バックプロパゲーションはその計算の順序が逆になります。出力層からスタートし入力層に至る向きで計算を進めます。
下記の式は現在の重み$w$から更新後の重み$w'$を求めるための式です。 誤差の大きさ$C$を小さくする方向に$w$、$b$を修正していくアルゴリズムです。 このような形で機械学習のパラメータを探索する方法を勾配降下法と呼びます。 $$ \begin{align} w' &= w - \eta \frac{\partial C}{\partial w} \tag 1\\ b' &= b - \eta \frac{\partial C}{\partial b} \tag 2 \end{align} $$ さて、この式で最も知りたいのは下記の2つの項の値です。 $$ \frac{\partial C}{\partial w_i} $$ $$ \frac{\partial C}{\partial b} $$ コスト関数$C$はTensorFlow Playgroundでは $$C=C(\phi)=\frac{1}{2}\left(\phi - y\right)^2 $$ の形をしているため、 $$\frac{\partial C}{\partial w_i}$$を計算するためには偏微分の連鎖律を使い式を変形する必要があります。 上式を下記のように変形します。 $$ \frac{\partial C}{\partial w_i} = \frac{\partial C}{\partial \phi} \frac{\partial \phi}{\partial w_i} = \frac{\partial C}{\partial \phi} \frac{\partial \phi}{\partial z} \frac{\partial z}{\partial w_i} $$ $C$, $\phi$は選び方は様々ですが、上記の式を見れば分かる通り、偏導関数が計算しやすいかどうかも選び方のファクターになります。
TensorFlow Playgroundeの初期設定では$C$, $\phi$は下記の通りとなっています。(コスト関数$C$は2017/1/24現在設定変更はできません) $$ C = \frac{1}{2} \left( \phi - y \right)^2\\ \phi = tanh(z)\\ $$ $y$: 真の出力
$z$: 1つのニューロンの入力総和 $= \displaystyle \sum_{i} \left(w_i x_i\right) + b$
この時 $$ \begin{align} \frac{\partial C}{\partial \phi} &= \phi - y \\ \frac{\partial \phi}{\partial z} &= \frac{\partial tanh(z)}{\partial z} = 1 - tanh^2(z)\\ \frac{\partial z}{\partial w_i} &= x_i \end{align} $$ となります。 ただし、この式の$$\frac{\partial C}{\partial \phi} $$の値は出力層のニューロンのみで計算できるものであることに注意してください。
コスト関数の定義$$C = \frac{1}{2} \left( \phi - y \right)^2$$を見れば分かる通り、この式中の$\phi$は出力層のニューロンの出力値を表したものであり、 隠し層のニューロンの出力、および重みの導出方法については別に考える必要があります。
なお、出力層のニューロンのみ考えた場合、 $$ \frac{\partial C}{\partial w_i} = \frac{\partial C}{\partial \phi} \frac{\partial \phi}{\partial z} \frac{\partial z}{\partial w_i} = (\phi - y)\left(1-tanh^2(z)\right)x_i $$ となります。
この値を求めるためにはトレーニングデータの真の値 $y$ の他に前の層からの入力総和 $z$ 、重みづけの対象である前の層からの入力 $x_i$ 、 および$\phi(z)$の値がわかっていなければなりません。 そのためバックプロパゲーションを走らせるためにはその前に少なくとも一度はニューラルネットワークの初期パラメータを使って 出力層のニューロンまで計算を終え、ニューロンの出力が分かっている状態にしておく必要があります。
上記では出力層の重み・バイアスについてしか計算できませんでした。
次は、隠し層の重み$w_i$、$b$を計算する方法、ひいては $$ \frac{\partial C}{\partial w_i} \\ \frac{\partial C}{\partial b} $$ の出力層に限定されない、より一般化した式の展開形について説明します。
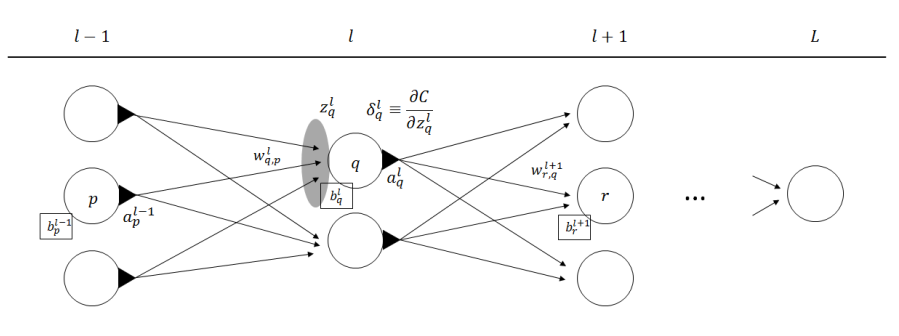
まずは上図のそれぞれの変数について確認します。ちなみに、上の図をクリックすると図が画面右上にポップアップします。 これ以降数式が文章中に度々表れますが、図を見ながらでないと何が書いてあるのか理解するのが難しいため、図を常に表示させた状態で 読み進めることを強く勧めます。
図の上部の$l-1, l, l+1, L$はそれぞれ層の番号です。$l-1$ 番目の隠し層、$l$、$l+1$ 番目の隠し層といった形で見てください。
$L$ 番目の層は出力層とします。
$b^{l}_{q}$ は層 $l$ の $q$ 番目のニューロンのバイアスです。
$w^{l}_{q,p}$ は層 $l$ の $q$ 番目のニューロンが層 $l-1$ の $p$番目のニューロンからの入力にかける重みです。
$a^{l}_{q}$ は層 $l$ の $q$ 番目のニューロンの出力です。活性化関数を$\phi$とすると
$$ a^{l}_{q} = \phi(z^{l}_{q})$$ となります。 $z^{l}_{q}$ は層 $l$ の $q$ 番目のニューロンが受け取る入力の総和です。ニューロンの入力は、前の層のニューロンの出力$a$を用いて $$ z^{l}_{q} = \sum_{k} \left( w^{l}_{q,k} \cdot a^{l-1}_{k} \right) + b^{l}_{q} $$ と表現できます。
さて、残りはひとつ、$\delta^{l}_{q}$です。
この変数が隠し層における重み$w_i$、バイアス$b$を計算するための鍵となる変数です。 $\delta^{l}_{q}$ を層 $l$ の$q$ 番目のニューロンのエラーと呼びます。 $$\delta^{l}_{q} := \frac{\partial C}{\partial z^{l}_{q}}$$ と定義します。意味としては、層$l$のニューロン$q$の入力総和$z^{l}_{q}$を微小量$\Delta z^{l}_{q}$だけ増やした時に増える誤差$\Delta C$の量です。
非常に興味深いのは最終出力と真の値の誤差関数である$C$の、最終的な出力層ではない中間の層の値の変動が$C$に与える影響についての式だということです。 当然ながら、$C$を$z^{l}_{q}$の関数で表現することは容易ではありません。しかし $$\delta^{l}_{q} = \frac{\partial C}{\partial z^{l}_{q}}$$ は非常に重要な式です。
なぜならば私達が最も知りたい$\dfrac{\partial C}{\partial w^{l}_{q,p}}$、$\dfrac{\partial C}{\partial b^{l}_{q}}$は、 ニューロンのエラー$\delta^{l}_{q}$を使って下記のように表せるからです。 $$ \begin{align} \frac{\partial C}{\partial w^{l}_{q,p}} &= a^{l-1}_{p} \delta^{l}_{q} \tag{3}\\ \frac{\partial C}{\partial b^{l}_{q}} &= \delta^{l}_{q} \tag{4} \end{align} $$ つまりニューロンのエラー$\delta^{l}_{q}$の値が分かれば、任意のニューロンの次のステップの重み$w^{l}_{q,p}$、バイアス$b^{l}_{q}$が求まるということです。
この章の残りは、上の(3),(4)の証明と、$\delta^{l}_{q}$の求め方になります。
説明の都合上、最初に$\delta^{l}_{q}$の求め方を説明したあと最後に(3),(4)を証明する順番で解説します。
lens $\delta$の求め方
$$\delta^{l}_{q} = \frac{\partial C}{\partial z^{l}_{q}}$$ のままではいくら式を眺めていてもどうすれば良いのか検討もつかないと思います。 そこで右辺を合成関数の偏微分の連鎖律を使い、下記のように変形します。 $$ \frac{\partial C}{\partial z^{l}_{q}} = \sum_{k} \frac{\partial C}{\partial z^{l+1}_{k}} \frac{\partial z^{l+1}_{k}}{\partial z^{l}_{q}} $$ $z^{l+1}_{k}$は層$l+1$の$k$番目のニューロンです。 この式は、層$l$のq番目の1つのニューロンの入力総和$z^{l}_{q}$の微小変化が最終誤差$C$に与える影響は 次の層$l+1$の全ニューロンの入力総和$z^{l+1}_{k}$の微小変化を用いて表現できることを示しています。
補足: 合成関数の偏微分の連鎖律
$x = x(t)$、$y = y(t)$が$t$で微分可能であり、$x$,$y$に関する2変数関数$f(x,y)$について$(x(t),y(t))$で微分可能であれば $$ \frac{\partial f}{\partial t} = \frac{\partial f}{\partial x} \frac{\partial x}{\partial t} + \frac{\partial f}{\partial y} \frac{\partial y}{\partial t} $$ これを$n$変数関数に拡張すると、
$x_1(t),\,x_2(t),\,...,\,x_n(t)$が$t$で微分可能であり、$x_1,\,...\,,x_n$に関する$n$変数関数$f(x_1,\,...,\,x_n)$について$(x_1(t),\,...,\,x_n(t))$で微分可能であれば
$$ \frac{\partial f}{\partial t} = \frac{\partial f}{\partial x_1} \frac{\partial x_1}{\partial t} + \frac{\partial f}{\partial x_2} \frac{\partial x_2}{\partial t} + ... + \frac{\partial f}{\partial x_n} \frac{\partial x_n}{\partial t} = \sum_{i}^{n} \frac{\partial f}{\partial x_i} \frac{\partial x_i}{\partial t} $$
次に、 $$ \delta^{l+1}_{k} = \frac{\partial C}{\partial z^{l+1}_{k}} $$ であるので $$ \sum_{k} \frac{\partial C}{\partial z^{l+1}_{k}} \frac{\partial z^{l+1}_{k}}{\partial z^{l}_{q}} = \sum_{k} \delta^{l+1}_{k} \frac{\partial z^{l+1}_{k}}{\partial z^{l}_{q}} $$ と書き換えることができます。
次に上式の右辺の $$ \frac{\partial z^{l+1}_{k}}{\partial z^{l}_{q}} $$ について考えます。入力総和$z$は重み$w$と前の層の出力$a$およびバイアス$b$を使って以下のように書けます。 $$ z^{l+1}_{k} = \sum_{j} \left( w^{l+1}_{k,j} a^{l}_{j} \right) + b^{l+1}_{k} = \sum_{j} \left( w^{l+1}_{k,j} \phi (z^{l}_{j}) \right) + b^{l+1}_{k} $$ 上記の $z^{l+1}_{k}$ を$z^{l}_{q}$で偏微分すると $$ \frac{\partial z^{l+1}_{k}}{\partial z^{l}_{q}} = \sum_{j} \left( w^{l+1}_{k,j} \frac{\partial \phi(z^{l}_{j})}{\partial z^{l}_{q}} \right) = w^{l+1}_{k,q} \frac{\partial \phi(z^{l}_{q})}{\partial z^{l}_{q}} = w^{l+1}_{k,q} \phi'(z^{l}_{q}) $$ と変形できます。ただし、$\phi'$は活性化関数$\phi$の入力総和$z$についての導関数です。
上式において、 $$ \frac{\partial \phi(z^{l}_{j})}{\partial z^{l}_{q}} = 0;\quad j \ne q $$ であることに注意してください。
図を見れば層$l$のニューロン$q$の入力総和$z^{l}_{q}$を変えたところで、 同じ層$l$の他のニューロンの出力 $\phi(z^{l}_{j})$ には影響が無いことはすぐに分かります。
よって $$ \delta^{l}_{q} = \sum_{r} \delta^{l+1}_{r} w^{l+1}_{r,q} \phi'(z^{l}_{q}) \tag 5 $$ となります。 この式は層$l+1$の全ニューロンのエラーと重みが分かっていれば、一つ前の層$l$のニューロンのエラーが求まることを示しています。
つまり、$l = L$の出力層のエラー$\delta^{L}$が分かれば、帰納的に出力層から入力層の向きに順々にニューロンのエラー$\delta^{l}$も求まるということです。
式$(5)$はバックプロパゲーションの名前の由来を物語っています。
なお、層$l$のエラーのベクトル表示は下記のようになります。 $$ \boldsymbol{\delta}^l = \boldsymbol \phi'(\mathbf{z}^l) \circ (\boldsymbol W^{l+1} \boldsymbol{\delta}^{l+1}) $$ ここで$\boldsymbol W^{l+1}$は層$l+1$の重み行列、$\boldsymbol{\delta}^{l+1}$は層$l+1$のエラーを列ベクトルで上から順に並べたものです。 $\circ$はアダマール積です。 $$ \boldsymbol \phi'(\mathbf{z}^l) = \left(\begin{array}{c} \phi'(z^{l}_{1}) \\ \phi'(z^{l}_{2}) \\ \cdots \\ \phi'(z^{l}_{q}) \\ \end{array}\right) \quad \boldsymbol W^{l+1} = \begin{pmatrix} w^{l+1}_{1,1} & w^{l+1}_{2,1} & \cdots & w^{l+1}_{r,1} \\ w^{l+1}_{1,2} & w^{l+1}_{2,2} & \cdots & w^{l+1}_{r,2} \\ \cdots \\ w^{l+1}_{1,q} & w^{l+1}_{2,q} & \cdots & w^{l+1}_{r,q} \end{pmatrix} \quad \boldsymbol{\delta}^{l+1} = \left(\begin{array}{c} \delta^{l+1}_{1} \\ \delta^{l+1}_{2} \\ \cdots \\ \delta^{l+1}_{r} \end{array}\right) $$
それでは出力層$L$のニューロンのエラーを求めてみましょう。これが分かれば帰納的に入力層までの全ニューロンについてエラーが計算できるようになります。
元々の定義より、 $$ \delta^{L}_{s} = \frac{\partial C}{\partial z^{L}_{s}} $$ です。ここで$s$は出力層$L$の$s$番目のニューロンです。
偏微分の連鎖律を使ってこの式を変形します。 $$ \frac{\partial C}{\partial z^{L}_{s}} = \frac{\partial C}{\partial a^{L}_{s}} \frac{\partial a^{L}_{s}}{\partial z^{L}_{s}} $$ ここで、誤差関数$C$および活性化関数$a = \phi(z)$は事前にその形を $$ C = \frac{1}{2} \left( a - y \right)^2 $$ $$ a = \phi(z) = tanh(z) $$ と決めているので、 $$ \delta^{L}_{s} = \frac{\partial C}{\partial z^{L}_{s}} = (a^{L}_{s}-y)\left( 1 - tanh^2(z^{L}_{s}) \right) $$ と簡単に求まります。
lens $\frac{\partial C}{\partial w^{l}_{q,p}}=a^{l-1}_{p}\delta^{l}_{q}$ と $\frac{\partial C}{\partial b^{l}_{q}}=\delta^{l}_{q}$ の証明
ここまでで任意のニューロンのエラー$\delta^{l}_{q}$が求まるようになりました。
次はニューロンのエラー$\delta$で$\dfrac{\partial C}{\partial w^{l}_{q,p}}$と$\dfrac{\partial C}{\partial b^{l}_{q}}$ が計算できることを示します。
まずは$\dfrac{\partial C}{\partial b^{l}_{q}}=\delta^{l}_{q}$を証明します。
合成関数の連鎖律を使い、 $$ \frac{\partial C}{\partial b^{l}_{q}} = \sum_r \frac{\partial C}{\partial z^{l+1}_{r}} \frac{\partial z^{l+1}_{r}}{\partial b^{l}_{q}} $$ と変形します。層$l+1$のニューロン$r$の入力総和$z^{l+1}_{r}$は層$l$のニューロンが加えたバイアス$b$の影響を受けていることは図を見れば明らかです。 ここで、 $$ \frac{\partial C}{\partial z^{l+1}_{r}} = \delta^{l+1}_{r} $$ です。また、 $$ z^{l+1}_{r} = \sum_q w^{l+1}_{r,q} a^{l}_{q} + b^{l+1}_{r} $$ であるので $$ \frac{\partial z^{l+1}_{r}}{\partial b^{l}_{q}} = w^{l+1}_{r,q} \frac{\partial a^{l}_{q}}{\partial b^{l}_{q}} = w^{l+1}_{r,q} \frac{\partial a^{l}_{q}}{\partial z^{l}_{q}} \frac{\partial z^{l}_{q}}{\partial b^{l}_{q}} = w^{l+1}_{r,q} \frac{\partial a^{l}_{q}}{\partial z^{l}_{q}} $$ と変形できます。よって $$ \frac{\partial C}{\partial b^{l}_{q}} = \sum_r \frac{\partial C}{\partial z^{l+1}_{r}} \frac{\partial z^{l+1}_{r}}{\partial b^{l}_{q}} = \sum_r \delta^{l+1}_{r} w^{l+1}_{r,q} \frac{\partial a^{l}_{q}}{\partial z^{l}_{q}} $$ となります。式$(5)$から $$ \delta^{l}_{q} = \sum_{r} \delta^{l+1}_{r} w^{l+1}_{r,q} \phi'(z^{l}_{q}) \tag 5 $$ であるので $$ \therefore \frac{\partial C}{\partial b^{l}_{q}} = \delta^{l}_{q} $$ が導かれました。
同様に $$ \frac{\partial C}{\partial w^{l}_{q,p}} = a^{l-1}_{p} \delta^{l}_{q} $$ を求めます。 $$ \frac{\partial C}{\partial w^{l}_{q,p}} = \sum_r \frac{\partial C}{\partial z^{l+1}_{r}} \frac{\partial z^{l+1}_{r}}{\partial w^{l}_{q,p}} = \sum_r \frac{\partial C}{\partial z^{l+1}_{r}} \frac{\partial z^{l+1}_{r}}{\partial a^{l}_{q}} \frac{\partial a^{l}_{q}}{\partial w^{l}_{q,p}} $$ ここで $$ z^{l+1}_{r} = \sum_q w^{l+1}_{r,q} a^{l}_{q} + b^{l+1}_{r} $$ であるので $$ \frac{\partial z^{l+1}_{r}}{\partial a^{l}_{q}} = w^{l+1}_{r,q} $$ です。また $$ \frac{\partial a^{l}_{q}}{\partial w^{l}_{q,p}} = \frac{\partial a^{l}_{q}}{\partial w^{l}_{q,p}} = \frac{\partial a^{l}_{q}}{\partial z^{l}_{q}} \frac{\partial z^{l}_{q}}{\partial w^{l}_{q,p}} = \frac{\partial a^{l}_{q}}{\partial z^{l}_{q}} a^{l-1}_{p} $$ であるので $$ \therefore \frac{\partial C}{\partial w^{l}_{q,p}} = \sum_r \frac{\partial C}{\partial z^{l+1}_{r}} \frac{\partial z^{l+1}_{r}}{\partial a^{l}_{q}} \frac{\partial a^{l}_{q}}{\partial w^{l}_{q,p}} = \sum_r \frac{\partial C}{\partial z^{l+1}_{r}} w^{l+1}_{r,q} \frac{\partial a^{l}_{q}}{\partial z^{l}_{q}} a^{l-1}_{p} = \delta^{l}_{q} a^{l-1}_{p} $$ となります。
ここまで導出した式を下記にまとめます。 $$ \delta^{l}_{q} = \sum_{r} \delta^{l+1}_{r} w^{l+1}_{r,q} \phi'(z^{l}_{q}) $$ $$ \delta^{L}_{s} = \frac{\partial C}{\partial z^{L}_{s}} = (a^{L}_{s}-y)\left( 1 - tanh^2(z^{L}_{s}) \right) $$ $$ \frac{\partial C}{\partial w^{l}_{q,p}} = \delta^{l}_{q} a^{l-1}_{p} $$ $$ \frac{\partial C}{\partial b^{l}_{q}} = \delta^{l}_{q} $$ バックプロパゲーションではこれらの式より1ステップ後の重み$w'$とバイアス$b'$を計算します。